vSAN障害時のIO影響(停滞時間)の検証手順
目的
vSANのノード&ディスク障害を発生させてIOの停滞がどれくらい発生するのかを確認することを目的とします。
手順概要
vSAN上でWindows/Linux OSを稼働させ、ベンチマークツールでIO負荷をかけながら、パフォーマンスツールでIOをモニターします。
途中で意図的に障害を発生させてIOへの影響(停滞~復旧までの時間)を確認します。
vSANクラスタの準備
通常通りにvSANクラスタを準備します。
本検証では、vSAN 8.0U1 のOSA Hybridの4ノードクラスタを準備しました。
疑似障害の準備
vSAN PG のTeamingポリシー設定で、Active のvmnicを一つだけにしておきます。それ以外はUnusedに設定し、Standbyにはしません。
esxcli vsan
network list でvSAN用のvmkを特定します。
esxtop の n オプションで vsan vmk が利用するvmnicも特定しておきます。
Windows VMの準備
OSのインストール
まずは検証用のWindows OSをvSANクラスタ上に準備します。(検証用Windows VM)
IO計測をするVMDKは別で作成するため、Windows OS をインストールするVMDKはvSANでなくてもよいですが、
仮想マシンの構成ファイルをvSAN上に配置しておかないと後述の物理配置確認ができなくなります。(GUIに表示されない)
そのため、仮想マシンの構成ファイル(vmxファイルとか)はvSANデータストア上に配置しましょう。(Storage vMotionでディスク個別の配置が可能です)
検証用のVMDKを作成する
障害検証用のVMDK(vSAN DataStore)を作成し、Windows OSに新規ドライブとして認識させます。(本検証ではEドライブ)
検証用VMDKオブジェクトの物理配置を確認する
検証用VMDKを構成するvSANコンポーネントの物理配置を確認しておくきます。
vSphere
Client で検証用VMを選択し、監視タブ→vSAN→物理ディスクの配置、から確認できます。
※vSAN上に構成ファイルがないと該当項目が表示されないので、その場合はStorage vMotionで構成ファイルをvSANデータストアに移動させましょう。
検証用VMDKのコンポーネントを保持するESXiのうち、検証用VMが稼働していないESXiを特定し、このESXiを疑似障害用ESXiとします。
疑似障害用ESXiからすべての仮想マシンを退避させ、DRSを手動にしておきます。。
検証用ドライブのWrite Cache 設定を確認する
以下の記事を参考に、検証用ドライブのWrite Cacheの設定を確認する
※デバイスマネージャを起動して該当ドライブを右クリック→Properties→Policyから確認可能です。
※なお、IOMeterはFileSystemのCachingを考慮しない模様。
https://serverfault.com/questions/748679/iometer-avoid-caching-and-raw-devices
IOMeterのインストール
以下のダウンロードサイトからIOMeterをダウンロードしてインストールします。
本検証では最新版ではなく、2006.07.27 の i386版を選んで検証用Windows VMにインストールします。
ダウンロードサイト:
http://www.iometer.org/doc/downloads.html
IOMeterの負荷パターンを設定する
IOMeterを起動してテスト用の負荷パターンを作成します。
ベンチマークテストが目的ではないので一定期間IOが継続し、パフォーマンスモニターで観測できれば良いです。
以下はその一例です。
Disk Targets
タブにて疑似障害用に作成したドライブを選択します。(下図の例ではEドライブを指定)
※左側のTopology枠内にて先にマシンを選択しておく。
Maximum Disk
Sizeは4194304 (2GB)で設定しました。
※特に意味はなく適当です。

Network
Target タブは未設定(デフォルト)のままでよいです。
Access
Specifications タブで適当なIOパターンを選択します。
※下図例では32K Random Write 100% を選択していますが、適当でよいです。

Test SetupタブでIO負荷の稼働時間を設定します。
Run Timeの項目で負荷の稼働時間を設定します。検証期間に合わせて適当でよいです。(下図は120秒)
Ramp Up TimeはIO負荷が上がりきるまでの待ち時間であり今回の検証では必要ありません。
下図では5秒の待機時間を設定していますが、特に意味はないです。
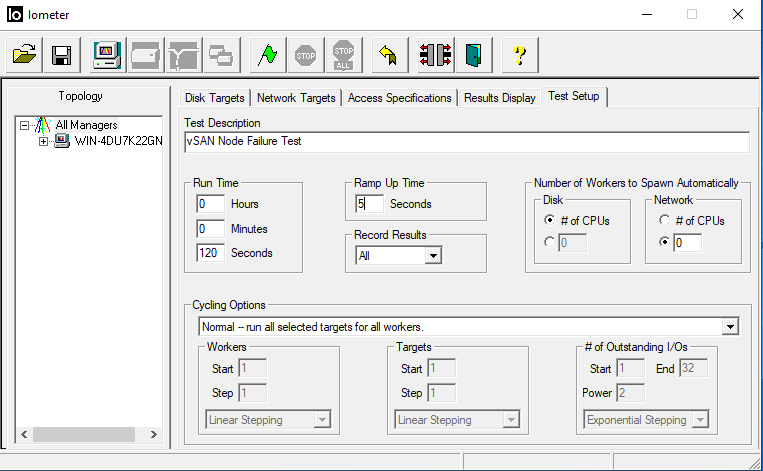
ここまで設定が出来たら保存ボタンで適当な名前・場所で保存しておくきます。
※次回からは設定ファイルを開くだけで同じIOを生成できるようになります。
負荷を生成してIO性能をモニターする
IOMeterでの負荷の生成
IOMeterでStart Testボタンを押してIOを生成します。

Resource MonitorでIOを確認する
CSVなどへの出力はできないがリアルタイムでモニターするだけであればPerformance MonitorだけでなくResrouce
Monitorで簡易的に確認することができます。
まずは、スタートメニューからリソースモニターを起動します。

Diskタブに移動します。

IO Meter を稼働させると Dynamo.exeというプロセスが検証用ドライブにIOをしている様子が確認できます。

Performance MonitorでリアルタイムのIO状況を観測する
Perfmon.mscを起動します。
※もしくはスタートメニュからPerformance
Monitorを起動します。
Performance
Monitorを選択し、+のアイコンからカウンターを追加します。(下図参照)

今回はIOを確認できれば良いので、追加するカウンターはPhysical Diskに関連するものから適当に選んでいます。(下図の例では
Disk Write Bytes/sec を選んでいる)
検証用VMDKを指定するためには Instances of selected object で該当のドライブを選びます。(本検証ではEドライブ)
選択が終わったら
Add >> で追加します。

Performance MonitorのData
Collector Setを作成して確認する
リアルタイムでの確認ではなく、あらかじめ取得する情報を設定して置き、結果はCSVファイルなどに出力して、あとから結果を確認する際に利用する方法です。
繰り返し実行する場合に便利な方法です。
詳細手順は以下の記事が詳しいのでご参照ください。
参考:
https://help.tableau.com/current/server/en-us/perf_collect_perfmon.htm
補足:
※CollectorのPropertiesから出力ファイルをCSVにしておきます(Commma
Separated)。
※保存先は検証の影響を受けないボリュームにしておきます。(IO遅延中の情報が記録されなくなることを防ぐため)
LinuxでIO負荷生成(fio)とIOをモニター(sar/dstat)する
テスト用Linux
VMを準備する
※準備についてはWindows VMの準備の項目も参照してください。
適当なLinux OSをvSANクラスタにデプロイします。
※本検証ではUbuntuを利用しました
※OSをsda(非vSANデータストア)にインストール
※テスト用ドライブをsdb (vSAN データストア)として/mnt にマウント(mkfsで適当にフォーマットしておく)
必要なパッケージ(sysstat/dstat/fio)をインストールしておきます。
Ubuntuの場合のコマンド例は以下です。
# apt-get install
sysstat
# apt-get install
dstat
# apt-get install fio
検証用VMDKオブジェクトの物理配置を確認する
検証用Windows VMの手順と同等のため割愛します。
IO負荷を生成する
fioで負荷を生成します。以下は実際のコマンド例です。
※2つの例で一貫性がないですが、ベンチマークが目的ではないのでご容赦ください。あくまでも障害影響を確認するためのIO生成が目的です。
バッファを利用しない場合の例:
# fio -filename=/mnt/test2g -direct=1 -rw=randwrite
-bs=4k -size=2G -numjobs=64 -runtime=300 -group_reporting -name=file1
参考:
fioを使ってストレージの性能を計測してみた
#Linux - Qiita
バッファを利用する場合の例:
# fio -filename=/mnt/buffered5M -direct=0 -rw=randrw
-rwmixread=20 -bs=4k -filesize=5M -numjobs=1 -runtime=300 -group_reporting
-name=test --ioengine=libaio -time_based
参考:
ベンチマーク fioでストレージの性能評価をためしてみた② ~評価編~ #Linux - Qiita
sarでモニターする
sarでモニターする場合は以下のようになります。
コマンド例:
# sar -b 1

dstatでモニターする
dstatでモニターする場合は以下のようになります。
コマンド例:
# dstat -tdr

vSANクラスタで疑似障害を発生させる方法
vSANアーキテクチャのどこで障害を発生させるかについて、この記事では詳細な説明をしませんが、HCIは基本的にノード単位の冗長性となっているため、ノード障害を考えるのが良いです。
また、案件によってはストレージという観点ではDisk障害時の影響を確認するのが必要なケースもありますので、ノード障害とディスク障害の検証方法例を説明します。
ノード障害を発生させる方法例(vSAN vmkernel port の切断)
ノード障害を発生させる方法はいくつか考えられますが、現地に行かずにリモートから実施でき、かつ負担の少ないものを紹介します。
冒頭の疑似障害の準備でvSAN
vmkernel portの冗長性を排除ずみとなっており、かつActiveとなっているvmnicまで特定できているため、
あとは、コマンドでvmnicをダウンさせればvSAN観点ではノード障害と同じ状態になります。
コマンド例:vmnic1をリンクダウン(障害用ESXiで実行)
# esxcli network nic down -n vmnic1
ディスク障害を発生させる方法例
vSANの機能(?)を利用して、ディスク障害を疑似的に発生させることも可能です。
参考:
VxRail ディスク障害試験について | DELL Technologies
vSAN 7.0 U2 Proof of Concept Guide | VMware
上記の記事にある通りにコマンドを実行すればvSANコンポーネントが存在するディスクを疑似的に抜去することができます。
該当ディスクのID(naa.xxxx)は、vSphere Client で検証用VMを選択し、監視タブ→vSAN→物理ディスクの配置、から確認できます。
コマンド例:naa.50000aaaabbbddddで疑似障害を起こす場合
疑似的に抜去するコマンド(疑似障害用ESXiで実行)
# python /usr/lib/vmware/vsan/bin/vsanDiskFaultInjection.pyc -u -d naa.50000aaaabbbdddd
元に戻すコマンド(疑似障害用ESXiで実行)
# esxcli storage core adapter rescan --all
# python /usr/lib/vmware/vsan/bin/vsanDiskFaultInjection.pyc
-c -d naa.50000398a88baddd
検証結果
本記事は障害時のIO停滞から復帰までの時間を確認する手順を紹介するものなので、実際の結果については載せません。
実際のIO影響はアプリケーションの動作やファイルキャッシュ等にも依存すると思います。
想定しているアプリケーションがある場合は、その環境を再現して実施するのが一番良いです。
おわりに
本記事ではvSANのノード障害とディスク障害時のIO停滞から復旧までの時間を確認する手順について、
vSAN環境の準備からGuestOSでの実行方法まで紹介しました。
本記事が何かの役に立てば幸いです。

コメント
コメントを投稿